Digitalisation is the process of converting analogue information and processes into digital form. This means digital technologies increasingly map and process paper documents, manual processes, and physical objects. For example, a handwritten report becomes a digital file. Standard operating procedures are no longer printed out but processed digitally by software programs. This is more efficient and more flexible. As a result, digitalisation speeds up information storage, processing and transmission. It leads to improved interaction between people and devices. Digitalisation is not only changing how we store data and communicate but also opening up new possibilities for how we design and control things.
Digital twin
One example of the application of digitalisation is the creation of a digital twin. A digital twin is a virtual model of a real object or system created by digitalising data. In materials research, this could mean that researchers develop a new material and use digital models and simulations to better understand the properties of that material. Data from actual experiments, measurements, and tests are captured digitally and combined into a virtual material representation. Digital twins follow an object through its entire life cycle. They use real-time data and apply simulations, machine learning, and intelligent analysis to facilitate decision-making. This allows them to examine more problems from different perspectives than traditional simulations. As a result, they offer greater potential for improving products and processes.[1] For more information, see our Digitalisation – From AI to Industry 4.0.
An electronic laboratory notebook (ELN) is a real-life example of a digital twin. An ELN is a system that helps researchers document their research work, e.g., by describing experimental procedures, performing sample preparation and calibration, and recording results. ELNs are designed to replace paper-based or handwritten lab notebooks, which have several disadvantages. For example, each person has a different style and standards for documenting data, resulting in inconsistent data quality. In addition, paper notes cannot be accessed remotely and are not automatically searchable. ELNs try to compensate for these disadvantages and ensure data transfer without loss.
Example of ELNs:
Chemotion, Karlsruhe Institute of Technology (KIT)
Sciformation, Sciformation Consulting GmbH; Originally started with the Max-Planck-Institute für Kohlenforschung
Digitalisation itself provides the basis for such innovative approaches. It makes it possible to collect and analyse large amounts of data, leading to the development of new tools. These tools help better understand and optimise real objects or processes, whether in materials research or other areas. Digital twins can help manufacturers decide what to do with products at the end of their life cycle and whether they can be recycled or processed in some other way. Furthermore digital twins can help determine which product materials are reusable.
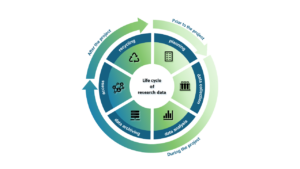
Research design phase: What happens before the project starts?
Research data management starts with the design concept long before any research data is generated. At this stage, researchers decide what data or data sets they want to collect and what guidelines to follow when handling their data. Many scientific institutions, stakeholders, or research communities have their own guidelines and make them available to the scientific community or students. They usually contain detailed instructions on good scientific practice, the handling of research data, and the definition of research data rights. For more information, see our article Guidelines for good research data management.
The FAIR (Findable, Accessible, Interoperable, and Reusable) principles are among the most important guidelines for handling research data in the scientific community. FAIR means data should be made findable, accessible, interoperable, and reusable wherever possible. However, unlike “open data”, it is not necessarily fully and freely available to everyone It may be kept restricted to protect trade secrets, patents, etc. See our article ”Standardised data and FAIR principles” for more information.
A data management plan supports sustainable research data management before, during, and after the project period. It is a formal document that records the life cycle of the data. This plan can change and evolve as conditions or requirements change during the project.
Research phase: research data management during the project
In the implementation phase, research data management focuses on collecting and analyzing original data. In this phase, researchers carry out experiments, measurements, and simulations and obtain original data from them. Original data are research data that are generated or used in the planning, execution, or documentation of scientific projects. The subsequent analysis of original data involves more than just the evaluation of measurement results. It also involves examining, validating, and describing the original data obtained and providing metadata. Metadata describes the original data and provides the context in which the dataset was created. The reusability of research data depends to a large extent on the quality of this descriptive metadata.
The analysis process also includes digitalising and translating data, or anonymizing certain data sets. Those responsible must decide how and where the data will be stored, such as on a physical or virtual server, and whether specific software should be used to back up the data.
Once scientists have collected and carefully analyzed enough data, they combine it into data sets. Depending on their intended use, they can now prepare the datasets for targeted sharing or publication. At this point, researchers or administrators should determine who can access the datasets and under what conditions. Each research dataset is given a unique persistent identifier (PID) by the database or journal in which it is published. An identifier is essential for making a dataset easily findable When researchers publish their data, they have to consider data rights and select an appropriate data license. This data license outlines the specific conditions under which others can access this data.
After the research project ends: How can we further use the data?
According to good scientific practice, researchers must archive their research data and make it available. The publication and archiving of data should begin during the research phase but take on additional importance once the research is complete.
Data is converted into appropriate formats and stored on proper platforms. For example, an individual may store their analysed data on the group server so that others can access the original data. Alternatively, they can store the data on a secure data-sharing platform, which is also used for backup.
Researchers should manage research data throughout its lifecycle so that it can be reused and applied in other research projects. A new research project could build on data from a previous project. This helps to assist those involved in the new project, helping them avoid starting from scratch or repeating past mistakes.
Further information: