Unsichtbare Forschungsdaten: Die Bedeutung von Standardisierung
Forschungsdaten bleiben unsichtbar, wenn sie nicht elektronisch abgespeichert werden. Daten können auch aufgrund unstrukturierter Datenformate, lokaler Standards oder aufgrund der begrenzten Bereitschaft Daten zu teilen, weder wiederverwendbar noch maschinenlesbar sein1. Dazu zählen unter anderem detaillierte Versuchsanleitungen, genaue Geräteeinstellungen oder Analysenergebnisse. Solche „Lücken“ im Forschungsdatenmanagement machen es schwer, Daten zu reproduzieren und führen zu Zeit- und Ressourcenverlust.
Um Forschungsdaten wiederverwendbar zu machen, muss man sie standardisieren und harmonisieren. Oder man macht sie FAIR, damit die wissenschaftliche Gemeinschaft Daten auf die bestmögliche Weise verwenden und teilen kann. Dabei geht es zunächst darum, Daten so vor- und aufzubereiten, dass sie für eine Zusammenarbeit mit Kollegen gut wiederverwertet werden können. Um Daten vor Missbrauch durch Parteien mit konkurrierenden Interessen zu schützen, können verschiedene Ebenen von Zugriffsrechten definiert werden, um einen Zugang zu erteilen oder zu sperren.
Was sind „FAIRe Daten“ und wie trägt das FAIR-Prinzip dazu bei, Daten harmonisiert und fortdauernd bereitzustellen?
Die FAIR-Prinzipien
Laut der Go-FAIR Initiative bedeuten die vier FAIR-Prinzipien, dass Forschungsdaten optimal organisiert, zugänglich und überprüfbar sind, und zwar für Menschen und Maschinen. Das soll jedoch nicht heißen, dass die Daten uneingeschränkt nutzbar und zugänglich sind. FAIR-Daten sind nicht dasselbe wie Open Data!
Das Akronym FAIR steht für Findable (auffindbar), Accessible (zugänglich), Interoperable (für die Zusammenarbeit nutzbar, interoperabel) und Reusable (wiederverwendbar).
Die FAIR-Prinzipien und ihre Verknüpfungen untereinander
Auffindbarkeit (Findability)
Die Auffindbarkeit ist der wichtigste Aspekt wiederverwendbarer Daten. Forschende müssen ihre Forschungsdatensätze mit aussagekräftigen und umfassenden standardisierten Zusatzinformationen beschreiben, die strukturierten Eigenschaften zum Verständnis des Datensatzes liefern. Diese Informationen bezeichnet man als Metadaten. Je umfassender die Metadaten sind, desto besser ist die Sichtbarkeit der Forschungsdaten. Es ist wichtig, Metadaten mit einem klaren Vokabular bereitzustellen, um Mehrdeutigkeiten zu vermeiden und eine effiziente Suche zu ermöglichen. Einfache Metadaten können z.B. der Name des Autors, das Erstellungsdatum der Datei, der Dateityp oder die Dateigröße sein. Je spezifischer die Metadaten sind, desto mehr Informationen können sie zum Verständnis eines Datensatzes beitragen. Ein Beispiel hierfür ist die Untersuchung der Biegefestigkeit eines neuen Materials. Damit kann man untersuchen, wie viel Spannung ein Material unter Biegung aushalten kann, bevor es bricht. Um die Ergebnisse solcher Tests nachvollziehbar und reproduzierbar zu machen, müssen Forschende umfassende Metadaten zu den verwendeten Materialien, den Testbedingungen und den Ergebnissen dokumentieren. Zum Beispiel werden die entsprechenden Metadaten des Tests erklären, wie sich die Biegefestigkeit von Porzellankeramik von der von Keramik unterscheidet, die in Baumaterialien wie Dachziegeln verwendet wird.
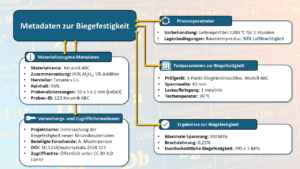
Um die Datenintegration zu verbessern, müssen Metadaten mit global eindeutigen und anhaltenden dauerhaften Identifikatoren (Kennungen oder engl. persistent identifiers, PIDs) verknüpft werden. Eine Kennung funktioniert wie ein Internetlink. Ein Beispiel für eine häufig verwendete Kennung ist der Digital Object Identifier (DOI), mit den wissenschaftlichen Publikationen und Forschungsdatensätze eindeutig gekennzeichnet sind. Wenn ein Datensatz in einer Datenbank (engl. Repository) veröffentlicht wird, erhält er einen DOI, der ihn eindeutig identifiziert, auch wenn sich der Speicherort der Daten ändert. Viele Datenbanken generieren automatisch einen solchen Identifikator, was die Sichtbarkeit der Daten verbessert und es anderen Forschenden ermöglicht, auf diese Daten zu verweisen.
Angenommen, eine Materialforschungsgruppe hat einen Datensatz zur Biegefestigkeit eines neu entwickelten Werkstoffs veröffentlicht. Die Forschende laden die Daten in ein öffentlich zugängliches Repository wie Zenodo oder Figshare hoch und erhalten dann den DOI 10.1234/materialdata.2024.123. Forschende nutzen diesen DOI, um direkt auf den Datensatz zuzugreifen und ihn in wissenschaftlichen Publikationen zu zitieren. Sogar Jahre später kann der Datensatz unter diesem DOI gefunden werden, da er in das DOI-System eingebunden ist und es stets auf die aktuellen Speicherorte verweist. Da die Metadaten und die Forschungsdaten zwei verschiedene Informationspakete sind, müssen die Metadaten eine eindeutige Kennung erhalten, auf welche Forschungsdaten sie sich beziehen.
Umfangreiche Metadaten und Identifikatoren reichen allein nicht aus, um Forschungsdaten auffindbar zu machen, wenn niemand von ihrer Existenz weiß. Die Indizierung ist eine Möglichkeit, digitale Ressourcen für Suchmaschinen und damit auch für andere Forscher sichtbar zu machen. Internet-Suchmaschinen können den Inhalt von textbasierten Dateien und bestimmten verschlüsselten Dokumentformaten „lesen“ (verarbeiten) und indizieren. Dadurch können Nutzende die Daten in den Suchergebnissen, beispielsweise über die Google Suche, finden, wenn sie nach einem bestimmten Begriff suchen.
Um Daten FAIR zu gestalten, reicht es nicht aus, dass Nutzende wissen, wie sie die Daten finden. Sie müssen auch darauf zugreifen können. Dies wird durch die Zugänglichkeit beschrieben.
Zugänglichkeit (Accessibility)
Auffindbare Daten bedeuten nicht automatisch zugängliche Daten. Ein Datensatz kann zwar gefunden werden, aber man braucht vielleicht eine spezielle Erlaubnis, eine Lizenz oder eine vorangehende Registrierung und Anmeldung auf einer Webseite, um auf ihn zugreifen zu können. In der Materialforschung bedeutet das z.B., dass Daten über die Biegefestigkeit eines neuen Materials in einer Datenbank gespeichert sind, aber man kann sie nur über einen protokollierten Authentifizierungs- und Autorisierungsprozess abrufen. Diese Protokolle (am häufigsten http(s) oder ftp) sollten kostenlos und weltweit nutzbar sein, damit die Daten und deren Beschreibung (Metadaten) zugänglich sind. Zugängliche Daten bedeuten jedoch nicht, dass sie „offen“ oder „frei“ sind. Protokolle sollten die Zugänglichkeit der Daten maximieren und die genauen Bedingungen angeben, unter denen diese Daten zugänglich sind.
Selbst wenn der ursprüngliche Datensatz nicht mehr verfügbar ist, sollten die Metadaten weiterhin verfügbar bleiben. So können Forschende immer noch herausfinden, wer die Daten gesammelt hat und welche Artikel dazu veröffentlicht wurden. Dies hilft beispielsweise dabei, die Erzeuger der Originaldaten zu finden. Diese können dann den Zugang zum Originaldatensatz bereitstellen.
Interoperabilität (Interoperability)
Die Daten und Metadaten sollten für Maschinen ohne spezielle Hilfsmittel lesbar sein. Daten sollten mit anderen Datensätzen, Systemen und Tools verknüpft oder verarbeitet werden können. Eine funktionierende Interoperabilität stellt sicher, dass Daten und Metadaten in unterschiedlichen Anwendungen und Forschungskontexten verwendet und kombiniert werden können.
Ein Kriterium dafür ist eine allgemein anwendbare und formale, für die wissenschaftliche Gemeinschaft zugängliche Sprache. Sie sollte unabhängig von den Forschenden oder der Forschungseinrichtung sein. Für die Daten sollten Wissenschaftlerinnen und Wissenschaftler einen standardisierten und definierten Wortschatz und Ontologien verwenden, damit andere sie konsistent und zuverlässig interpretieren können. Um diese Materialforschungsdaten interoperabel zu machen, verwendet man international anerkannte Materialbegriffe und -formate. So können Forschende und Maschinen die Materialdaten mit anderen Datensätzen kombinieren, und über die Verknüpfungen zwischen Datensätzen neue Informationen gewinnen.
Zudem sollten Metadaten mit anderen Daten und anderen Metadaten verknüpft werden. Diese Verknüpfungen sollten die Verbindungen zwischen den Datensätzen beschreiben, um die Sichtbarkeit zu erhöhen und eine korrekte Quellenangabe zu ermöglichen.
Wiederverwendbarkeit (Reusability)
Wir haben bereits im Abschnitt Zugänglichkeit besprochen, wie man auf Daten zugreifen kann. Im Abschnitt Wiederverwendbarkeit wird erläutert, wer die Daten verwenden darf. Dies wird auch als rechtliche Interoperabilität bezeichnet. Gängige Datennutzungslizenzen definieren die Bedingungen, unter denen die Daten wiederverwendet werden dürfen. Die bekanntesten Lizenzbeispiele sind MIT oder Creative Commons. Diese Lizenzen legen beispielsweise fest, dass die Daten für Forschung und Entwicklung genutzt werden dürfen, solange der ursprüngliche Autor oder die Institution zitiert wird. Dadurch können andere Forschende Daten in ihren Studien verwenden, ohne weitere Genehmigungen einholen zu müssen. Je mehr aussagekräftige Attribute an einem Datensatz anhängen, desto einfacher können sie gefunden und wiederverwendet werden. Die Anzahl und Qualität der Attribute kann man durch die Bereitstellung von Metadaten erhöhen. Diese beschreiben den Kontext, wie z.B. ein Versuchsprotokoll oder Parametereinstellungen. Wiederverwendbare Daten bedeuten auch, dass Anwendende wissen, welche Nutzungsrechte mit den jeweiligen Daten verbunden sind und woher diese stammen.
Wissenschaftlerinnen und Wissenschaftler können Daten effizienter wiederverwenden, wenn sie harmonisiert sind. Das bedeutet, dass sie beispielsweise eine gemeinsame Vorlage und ein gemeinsames Vokabular verwenden und den gleichen Datentyp haben. So kann man Materialforschungsdaten effektiver (wieder)verwenden, wenn sie den etablierten Standards in der Materialforschung, z.B. ASTM-Standards für mechanische Prüfung von Keramiken entsprechen.
Durch diese Maßnahmen ist der Datensatz im besten Fall so strukturiert, dass er nicht nur zugänglich und verständlich ist, sondern auch ohne zusätzliche Anpassungen direkt in weiteren Projekten verwendet werden kann, z. B. für die Entwicklung ähnlicher Materialien oder zur Modellierung von Materialeigenschaften in Simulationen.
Welche Erkenntnisse liefern die FAIR-Daten?
Das Ziel der FAIR-Initiative ist es, qualitativ hochwertige, standardisierte Daten bereitzustellen, die langfristig wiederverwendet werden können. FAIR-Daten sollen die Forschung besser organisieren und helfen, neue Erkenntnisse schneller zu gewinnen. Dies spart Zeit und Ressourcen. Sie sollen auch Sichtbarkeit verbessern, was wiederum die Zusammenarbeit fördern kann. Darüber hinaus bieten sie einen Integritätsnachweis, der Fehlverhalten vermeidet.
Der Prozess, der schrittweise beschreibt, wie wir FAIRe Daten erreichen können, ist der FAIRification-Prozess . Einen praktischen Leitfaden dafür bietet das Three-point FAIRification Framework .
Weiterführende Informationen:
- Wilkinson, M. D.; Dumontier, M.; Aalbersberg, I. J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L. B.; Bourne, P. E.; et al. Sci Data 2016, 3, 160018.
- GO FAIR International Support and Coordination Office (GFISCO). FAIR Principles – FAIR Guiding Principles for scientific data management and stewardship’. 2021. https://www.go-fair.org/fair-principles/ (accessed 25.10.2024).
- Riley, J. Understanding Metadata: What is Metadata, and What is it For?: A Primer. National Information Standards Organization (NISO), 2017. https://groups.niso.org/higherlogic/ws/public/download/17446/Understanding%20Metadata.pdf (accessed 24.10.2024).
- European Commission. H2020 Programme Guidelines on FAIR Data Management in Horizon 2020. July 2016. https://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pilot/h2020-hi-oa-data-mgt_en.pdf (accessed 30.10.2024).
- Landi, A.; Thompson, M.; Gianuzzi, V.; Bonifazi, F.; Labastida, I.; da Silva Santos, L. O. B.; Roos, M. Data Intelligence 2020, 2, 47-55
- Bayerlein, B.; Schilling, M.; Birkholz, H.; Jung, M.; Waitelonis, J.; Mädler, L.; Sack, H. Materials & Design 2024, 237, 112603.
- Margoni, Thomas and Peters, Diane, Creative Commons Licenses: Empowering Open Access (March 10, 2016). Available at SSRN: https://ssrn.com/abstract=2746044 or http://dx.doi.org/10.2139/ssrn.2746044
- Rocca-Serra, P.; Gu, W.; Ioannidis, V.; Abbassi-Daloii, T.; Capella-Gutierrez, S.; Chandramouliswaran, I.; Splendiani, A.; Burdett, T.; Giessmann, R. T.; Henderson, D.; et al. The FAIR Cookbook – the essential resource for and by FAIR doers. Sci Data 2023, 10, 292.
- Welter, D.; Juty, N.; Rocca-Serra, P.; Xu, F.; Henderson, D.; Gu, W.; Strubel, J.; Giessmann, R. T.; Emam, I.; Gadiya, Y.; et al. Sci Data 2023, 10, 291. DOI: https://doi.org/10.1038/s41597-023-02167-2.